A concrete implementation of the Small Architecture
Posted | mna.dev
A few months ago, I posted Small is Beautiful (The Developer’s Edition), where I outlined my philosophy on building human-scale, minimal-but-thorough web systems that can be fully understood by anyone on the engineering team.
Fast-forward to today and I have implemented and launched a system built exactly with this approach. This post will give technical details on the implementation and the ongoing operations and maintenance of the system.
A Search Engine for Heavy Metal Reviews
The website I created is fiends.io, it is a search engine specialized for heavy metal album reviews (yes, it is very niche).
The tech stack is the same as mentioned in my previous post:
- Everything except the web frontend is implemented in Lua 5.4, including the deployment script and other helper scripts. The system is based on my tulip framework (built on top of lua-http, cqueues and luapgsql), and the lua-gumbo and neturl libraries also play important parts.
- The database is postgresql, and the message queue, scheduled tasks (cron jobs), and full-text search features are also built on postgresql.
- The Operating System is Linux (the Fedora distribution), and systemd is used to run the various processes as services (the database and web server, but also the crawler - or “bot” - that visits the websites for reviews to index, and the worker process that consumes the messages from the queues).
- The caddy web server is used in front of the actual Lua web server to handle automatic TLS certificate management and to serve static assets.
- The web frontend is very light on javascript and CSS, I used the chota CSS framework as minimal starting point and vanilla javascript for the few features that need it (no framework). The feather icons library is used for icons, and the js-cookie library to manage the sole cookie.
The “build” step for the frontend is simply a Makefile to minify the javascript/CSS files with a helper Lua script that generates the hashes and renames the files with the corresponding hash for cache-busting purposes. It doesn’t need npm/node. Google’s PageSpeed Insights is consistently between 95-100 for both the home page and the search results page.
Development
The idea for the website came in early January 2021, and my first commit is on January 17. I must admit I’m surprised at how fast it went, given that this is a side-project - but I should mention that a) I did allocate quite a bit of personal time to it, as it was a lot of fun to work on and b) this is a domain in which I have a lot of prior experience (servers, message queues, crawling, etc.).
By February 26, a “register your email to be notified when it launches” page was live, and during that time the backend processes were hard at work indexing pages. By late March (24, I think), the site was launched.
As of this writing, it has visited close to 100 000 distinct URLs and indexed over 40 000 reviews, without any significant glitch. The backend has been robust, reliable and efficient.
Operations
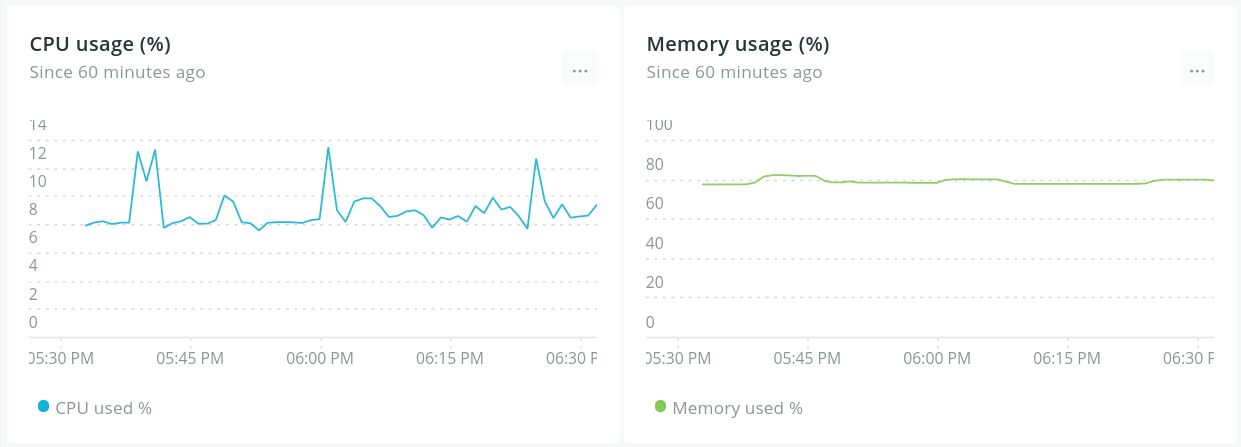
The whole system currently runs comfortably on a small 5$/month Virtual Private Server (VPS) with 1 vCPU, 1GB of RAM and 25GB of disk space. Under normal load with active crawling and indexing of pages going on, it runs at under 10% of CPU usage and at around 75% of memory. I expect disk space to be the first thing to require an upgrade, as more and more links are crawled, the database grows relatively big.
Memory usage is pretty normal (if a bit high, but again, this is only a 1GB RAM server), and I haven’t noticed any concerning constant growth that would indicate leaks. Although I do redeploy quite often, it has run for multiple days without interruption at times without any resource issues.
Speaking of deployment, I have a custom command-line tool that automates this (in Lua) and it supports:
- Deploying to various providers (currently it supports two, Linode and Digital Ocean, but others could be added quickly as long as they have an API or a command-line tool to automate tasks, and a few basic features that are required across all providers).
- Creating a new image and server. This scenario takes the longest time to complete (around 30-40 minutes), it starts by creating a server, installing the required programs, creating an image from it and then creating another server from that image, where the code will be deployed. Once done, new servers can be created quickly from the saved image.
- Creating just a new server from an existing image. This typically takes less than 10 minutes.
- Deploying code to an existing server. This takes just a few seconds (like 5-10 seconds), and during that time, the caddy server will respond to requests with a 502 page indicating that the website is in maintenance mode.
- Restoring an existing database backup to an existing server. This can take 15-30 minutes depending on the size of the backup and the transfer speed, and then the restore operation itself.
One thing that isn’t automated via this tool yet is upgrading a server (in terms of CPU/RAM/disk space), but this is straightforward enough through the web UI of the providers (it requires a shutdown of the server, a resize, and a reboot, so it can take 15-20 minutes).
It’s good to know the various options for an emergency scaling or to recover from an unexpected failure, and to prepare and test them beforehand, which is what I have done and why I have a rough idea of the duration for each task. For a non-critical website like this where the worst that can happen is to lose the last few hours of crawling data (which will be retried automatically following a database restore), I’m fine with those recovery delays.
I have a systemd timer on the server that takes care of taking database backups on a daily basis and storing them safely outside the server (I use Backblaze B2 Cloud Storage for that). The backup is also stored as the weekly backup on the first day of each week, and as the monthly backup on the first day of the month.
It’s also good to know the potential capacity of the server, and to that end I ran some load testing and benchmarks, and applied rate limiting on the web server so that it doesn’t try to handle more than it can take. I went a step further and added support for a “degraded search” experience: under heavy load, before rejecting requests, it will accept a number of other requests in that “degraded” mode where thumbnails are not returned along with the search results.
Conclusion
I have started many, many, many side-projects in my life, and abandoned a lot of them at various stage of completion, chasing the next interesting thing to work on. I’m pleasantly surprised at how quickly I managed to bring this one - a pretty ambitious one I must add - to “completion” (of course it’s never really “done”, I have lots of ideas for future evolution).
YMMV and the details may differ, but for me at least, I’m absolutely convinced that the fact that I used a small, simple and easy to grasp infrastructure and architecture, coupled with a fun tech stack that I felt good coming back to even when there were hard problems to solve, helped me get to launch.